Improving the Effectivness of Traceability Link Recovery using Hierarchical Bayesian Networks
Authors
- Kevin Moran, William & Mary
- David N. Palacio, William & Mary
- Carlos Bernal-Cardenas, William & Mary
- Daniel McCrystal, William & Mary
- Denys Poshyvanyk, William & Mary
- Chris Shenefiel, Cisco Advanced Security Research Group
- Jeff Johnson, Cisco Security and Trust Engineering
Project Overview
This website serves as an online companion to the ICSE'20 paper entitled "Improving the Effectiveness of Traceability Link Recovery using Hierarchical Bayesian Networks". This site includes expanded material from the evalaution as well as links to Data and Code.
Video Overview
Link to Preprint
Code & Data
Below we provide links to the Comet data set and replication package, as well as the code repository for our implementation of the Comet both as an extensible Python library and a Jenkins plugin.
The Comet Model
To help aid in the comprehension of COMET’S underlying model, we provide a graphical representation using plate notation in Fig. 1, which we use to guide our introduction and discussion. The model in Fig. 1 is computed on a per link basis, that is between all potential links between a set of source (S) and target artifacts (T).
 Figure 1: Plate Diagram of Comet's Hierarchial Bayesian Network
Figure 1: Plate Diagram of Comet's Hierarchial Bayesian Network
We use S and T to refer to a single source and target artifact of interest respectively. COMET’S probabilistic model is formally structured as an HBN, centered upon a trace link prior θ which represents the model’s prior belief about the probability that S and T are linked. Our model is hierarchical, as the trace link prior is influenced by a number of hyperpriors, which are in constructed in accordance with a set of hyper-parametersthat either derived empirically, or fixed. In Fig. 1, hyperpriors are represented as empty nodes, and hyper-parameters are represented as shaded blue nodes. In general, empty nodes represent latent, or hidden, variables whereas shaded nodes represent variables that are known or empirically observed quantities. The rectangles, or “plates” in the diagram are used to group together variables that repeat.
To make our model easier to comprehend, we have broken it down into four major configurations, which we call stages, indicated by different colors in Fig. 1. The first stage of our model (shown in blue at top) unifies the collective knowledge of textual similarity metrics computed by IR techniques. The second stage (shown in orange in middle) reconciles expert feedback to improve the accuracy of predicted trace links. The third stage (shown in green at bottom) accounts for transitive relationships among development artifacts, and the fourth stage combines each of the underlying complexities. It should be noted that the first stage of our model can be taken as the “base case” upon which the other complexities build and is always required to predict the existence of a trace link.
The Comet Jenkins Plugin
The screenshots below illustrate the User Interface of the Jenkins plugin that was used to evaluate Comet during the user study.

The above screenshot shows the general front-end user interface for the automated traceability plugin we developed in collaboration with our industrial partner. The Comet HBN serves as the backend and provides information regarding the probability that a trace link exists between two given pairs of software artifacts. For the project indexed in the user interface above, Comet has analyzed source code test cases and requirements. The first dropdown menu provides the user with options to view potential links between differing artifact pairs.
The list of candidate trace links are shown just below the configuration drop down menus, and display a “base artifact”, the linked artifacts — as determined by Comet’s HBN — are shown in the middle of the list with the textual similarity from Stage 1 of Comet’s HBN shown directly next to the artifact. The rightmost column shows the artifact similarity of the final stage of Comet’s HBN, after taking into account developer feedback and transitive links.
This list can be generated and updated upon each trigger of Jenkins pipeline, which in turn can be triggered upon each commit to a project software repository. Comet maintains an cache of its HBN for each pair of artifacts and only has to recalculate changed artifact pairs as the project evolves, lending the tool well to agile projects that utilize CI/CD pipelines.

The above screenshot illustrates the traceability interface for examining potential links between requirements and test cases.

The above screenshot illustrates the sorting functionality of our traceability plugin. Developers or analysts using our tool are able to select from one of three categories: “Probably Linked” indicating a high artifact similarity score based on Comet’s HBN; “Unsure” or cases where the artifact similarity score fell within a standard deviation of the median similarity values for given set of artifact pairs; and “Probably Not Linked” where the the artifact similarity score was in the bottom quartile of similarity values for a given set of artifact pairs. This allows the developer to quickly shift between views and traceability tasks.

This screen shows the interface that allows developers or analysts to provide feedback for a given pair of artifacts. If no feedback has been previously been provided for an artifact pair, then the developer or analyst simply has to click on the “None” link to bring up the feedback modal dialog. This dialog presents the developer with five options for feedback. Each of these options maps to value to between [0,1] to indicate the level of confidence that a developer has in the link existing. These values are as follows: “Strongly Agree”=0.95, “Agree”=0.75, “Undecided”=0.5, “Disagree”=0.25, and “Strongly Disagree”=0.05.
This interface was selected to simplify the feedback process and make it quick and easy for developers to provide expert feedback to Comet’s HBN. In some instances, a developer or analyst may want to view the artifacts in question to make further determination regarding their similarity; thus the Comet plugin allows for the opening of artifacts in the pair by clicking on the hyperlinked artifact names at the top of the model dialog window.

The above screenshot illustrates the updated traceability after a developer or analyst has provided feedback via the modal dialog. We can observe that the “Feedback” entry for the top pair of artifacts now reads “Strongly agree” and the Artifact similarity score has been updated to account for this feedback, increasing the score by the amount stipulated by Comet’s HBN.

The above screen illustrates the links between source code files and test cases as determined by collecting runtime information via lightweight instrumentation during the automated testing process via the Jenkins pipeline.

During our limited deployment of the traceability tool with our industrial partner, we observed one highly desired use case from security professionals. This use case involved having the plugin display artifacts that were not linked to any other artifact according to Comet’s HBN. The intuition behind this feature is that such artifacts represents “suspicious” requirements or source code snippets that must be further inspected. The above screen shows the support that our Comet plugin provides for this use case, and it simply lists artifacts that are unlikely to have any link to any other artifact according to a predefined threshold (0.15 in our plugin implementation).
Empirical Study
Research Questions
- RQ1: How effective is Comet in terms of predicting candidate trace links using combined information from IR techniques?
- RQ2: To what extent does expert feedback impact the accuracy of the candidate links of Comet?
- RQ3: To what extent does information from transitive links improve Comet’s trace link prediction accuracy?
- RQ4: How effective is the Holistic Comet’s model in terms of predicting candidate trace links?
- RQ5: Do professional developers and security analysts find our implementation of Comet useful?
Study Context
The context of this empirical study includes the eight datasets shown in the table below. Six of these datasets are taken from the open source CoEST community datasets. Note that we do not use all available subjects in the CoEST repository, as we limited our studied systems to those that: (i) included trace links from requirements or use cases written in natural language to some form of code artifact, (ii) were written in English and/or included English translations, and (iii) had at least 1k LoC. We utilize two datasets to investigate and tune the hyper-parameters of Comet’s HBN, Albergate, and the Rq→Tests dataset of the EBT project. We utilize the other six datasets for our empirical evaluation. The subject system called "LibEST" is an open source networking related software project which was created and is actively maintained by our industrial partners at Cisco. The ground truth set of trace links between Rq→Src and Rq→Tests was created by a group of authors with feedback from engineers working on the project.
| Project | Description | Language | Size (LoC) | Artifacts | # Source Artifacts | # Target Artifacts | # of Artifact Pairs | # of Links |
|---|---|---|---|---|---|---|---|---|
| Tuning Projects | ||||||||
| Albergate | Hotel Management | Java | 10,464 | Rq→Src | 55 | 17 | 935 | 53 |
| EBT | Traceability Benchmark | Java | 1,747 | Rq→Tests | 40 | 25 | 1,000 | 51 |
| Experimental Projects | ||||||||
| LibEST | Networking Software | C | 70,977 | Rq→Src | 59 | 11 | 649 | 204 |
| Rq→Tests | 59 | 18 | 1,062 | 352 | ||||
| eTour | Tour guide management | Java | 23,065 | UC→Src | 58 | 116 | 6,728 | 308 |
| EBT | Traceability Benchmark | Java | 1,747 | Rq→Src | 40 | 50 | 2000 | 98 |
| SMOS | School Management | Java | 9,019 | UC→Src | 67 | 100 | 6,700 | 1044 |
| iTrust | Medical System | Java, JSP, JS | 38,087 | Rq→Src | 131 | 367 | 48,077 | 399 |
The “base” first stage of Comet’s HBN is able to utilize and unify information regarding the textual similarity of development artifacts as computed by a set of IR techniques. While there is techni- cally no limit to the number of IR techniques that can be utilized, we parameterized our experiments using the 10 IR- techniques enumerated in Table II. The first five techniques are standalone IR techniques, whereas the second five are combined techniques utilizing the methodology introduced by Gethers et al. This combined approach normalizes the similarity measures of two IR techniques and combines the similarity measures using a weighted sum. We set the weighting factor λ for each technique equal to 0.5, as this was the best performing configuration reported in the prior work. The other parameters for each of the techniques were derived by performing a series of experiments on the two tuning datasets, and using the optimal values from these experiments. For all IR techniques, we preprocessed the text by removing non-alphabetic characters and stop words, stemming, and splitting camelCase. Note that non-deterministic techniques such as LSI, LDA, and NMF were run over multiple trials.
| IR Technique | Tag | Model Parameters | Treshold Technique |
|---|---|---|---|
| Vector Space Model | VSM | N/A | Link-Est |
| Latent Semantic Indexing | LSI | k=30 | Link-Est |
| Jensen-Shannon Divergence | JS | N/A | Min-Max |
| Latent Dirichlet Allocation | LDA | # Topics=40 # Trials=30 |
Min-Max |
| NonNegative Matrix Factorization | NMF | # Topics = 30 | Median |
| Combined VSM + LDA | VSM+LDA | k=5 #Trials=30 λ=0.5 |
Link-Est |
| Combined JS+LDA | JS+LDA | k=5 #Trials=30 λ=0.5 |
Link-Est |
| Combined VSM+NMF | VSM+NMF | k=40 λ=0.5 |
Link-Est |
| Combined JS+NMF | JS+NMF | k=40 λ=0.5 |
Link-Est |
| Combined VSM+JS | VSM+JS | λ=0.5 | Min-Max |
IR Threshold Determination and Tuning
In order to accurately estimate the likelihood function Y for Comet’s HBN we need to choose a threshold ki for each IR technique that maximizes the precision and recall of the trace links according to the computed textual similarity values. To derive the best method for determining the threshold for each IR technique, we performed a meta evaluation on our two tuning datasets. We examined six different threshold estimation techniques: (i) using 1% of the ground truth, (ii) using the mean of all similarity measures for a given dataset, (iii) using the median of all similarity measures across a given dataset, (iv) using a Min-Max estimation, (v) a sigmoid estimation, and (vi) Link- Est, where an estimation of the number of confirmed links for a dataset is made based on the number of artifacts, and a threshold derived to ensure that the estimated number of links is above that threshold. We performed each of these threshold estimation techniques for all studied IR techniques across our two tuning datasets, and compared each estimation to the known optimal threshold. We used the optimal technique across our two tuning datasets, as reported in Table II.
- 1% of the Ground Truth: This technique simply utilizes 1% of the ground truth to find the optimal threshold for the sampled one percent. While this can be accurate, it requires some known existing links.
- Mean of Similarity Measures: This technique simply takes the mean of all the similarity measures as the threshold.
- Median of Similarity Measures: This technique simply takes the median of all the similarity measures as the threshold.
- Min-Max Estimation: This technique simply takes the Max value, subtracts the min value, and divides by two to determine a threshold.
- Sigmoid Estimation: This technique fits a sigmoid curve to the generated IR similarity values to determine a threshold.
- Link-Est (Simple Inference): For this technique, we assume a fixed number of artifacts are linked to each source artifact (e.g., requirements), then we multiply this number by the total number of source artifacts, and then divide by the number of target artifacts. This gives us a number N, and an optimal threshold is derived by ordering all similarity values in ascending order and taking the Nth similarity value.
We performed an extensive set of experiments to determine the optimal IR threshold technique to use on all datasets presented in the paper, however, we utilized the optimal settings only from our tuning datasets.
Empirical Results
RQ1 Results
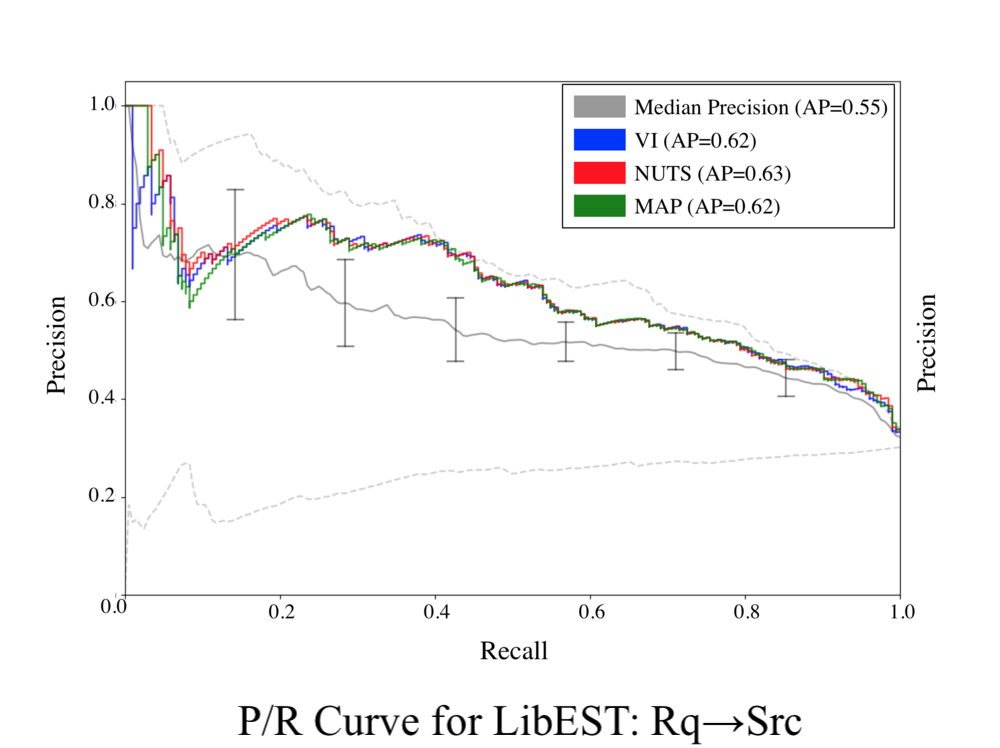
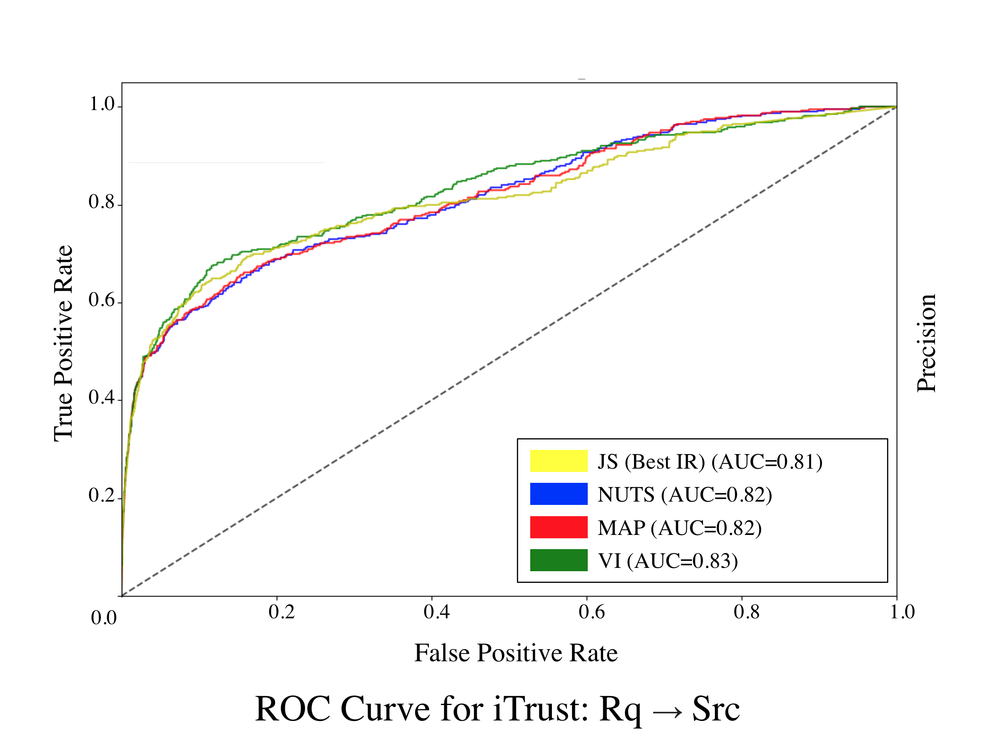
The results for Stage 1 of Comet’s HBN are provided in the P/R curves below. Stage 1 of Comet outperforms the median IR/ML baseline across all subjects, to a statistically significant degree according the p value of the Wilcoxon signed rank test. In some cases, such as for iTrust, LibEST, and eTour, Stage 1 of Comet significantly outperforms the median IR/ML baseline, and approaches the performance of the best IR/ML baseline. The P/R curve for the iTrust project, exhibits performance that outpaces the best IR/ML technique, particularly for lower recall values. Comet also outperforms the state of the art DL approach across all subjects, likely because the DL approach had difficulty generalizing semantic relationships across datasets.
These results signal remarkably strong performance for Comet’s Stage 1 model. Recall that, the Stage 1 model only utilizes observations taken from the set of ten IR/ML techniques introduced earlier, thus the fact that the Stage 1 model was able to consistently outperform the median IR/ML baselines and in some cases, nearly match the best IR/ML baseline indicates that Comet’s HBN is capable of effectively combining the observations from the underlying IR/ML techniques for improved predictive power. Most encouragingly, the first stage of our model provides consistent performance across datasets. IR techniques are notoriously difficult to configure for peak performance. Thus, a practitioner often cannot know a-priori what IR/ML technique, or configuration of that technique, will perform best on a given dataset, as there are no pre-existing links to make this determination. The results of the experiments on Stage 1 of Comet’s model illustrate that it significantly outperforms the median results for past IR/ML techniques, making Comet a highly practical approach that is likely to offer consistently good performance when applied to new projects.
Precision/Recall Curves
(Right click to download an image or open in new tab/window at full size)





ROC Curves





RQ2 Results
The P/R curves for all subject systems are shown below for each error rate (0%, 25%, 50%). In thses figures, the blue curve represents Stage 2 of Comet’s HBN and the red curve represents the results for Stage 1 for the randomly sampled set of 10% of the subject programs’ potential links. This figure illustrates that Stage 2 of Comet’s HBN is able to effectively incorporate expert feedback into its predicted trace link probabilities, as the Stage 2 model dramatically outperforms both the median and best IR techniques as well as the first stage of the model, even with an error rate of 25%. Furthermore, we see this trend continue across subjects for the 25% error rate, where the AP across all subjects for Stage 2 sampled links was 0.57 compared to 0.35 for Stage 1. However for larger error rates such as 50%, we see Stage 2 start to underperform Stage 1 where the AP across all subjects for Stage 2 sampled links was 0.33 compared to 0.35 for Stage 1. Finally, when considering all subjects with 0% error, Comet’s Stage 2 model unsurprisingly achieves perfect precision and recall for the sampled links. These results illustrate that Stage 2 of Comet’s HBN is able to effectively utilize expert feedback to improve its predictions.
Precision/Recall Curves for 0% Developer Error
(Right click to download an image or open in new tab/window at full size)






Precision/Recall Curves for 25% Developer Error
(Right click to download an image or open in new tab/window at full size)






Precision/Recall Curves for 50% Developer Error
(Right click to download an image or open in new tab/window at full size)

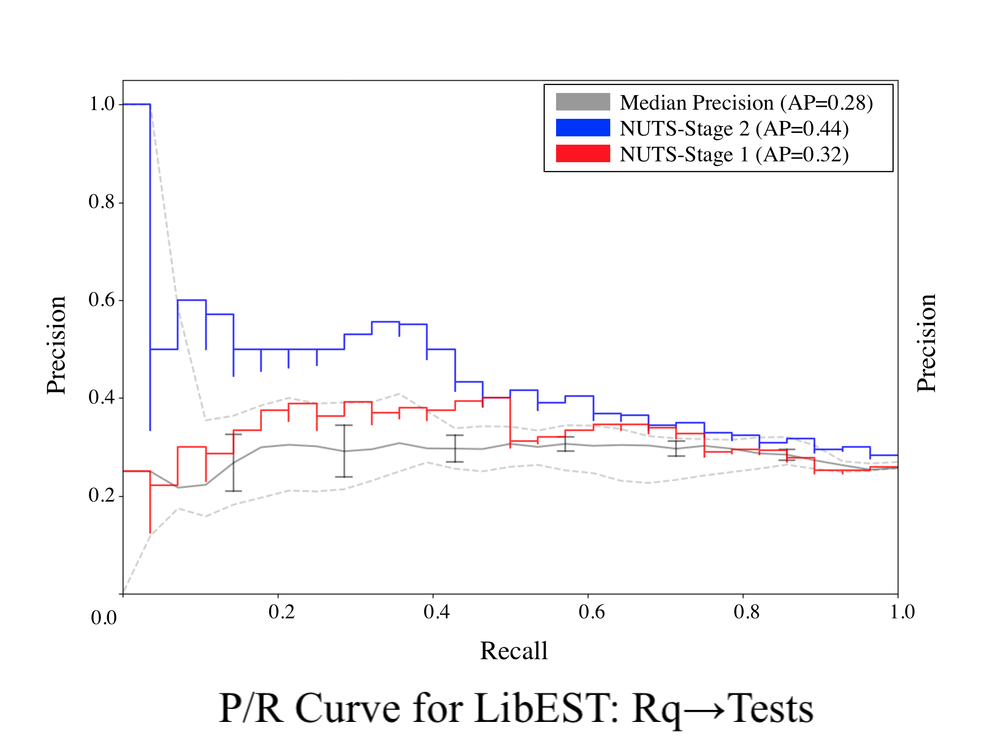
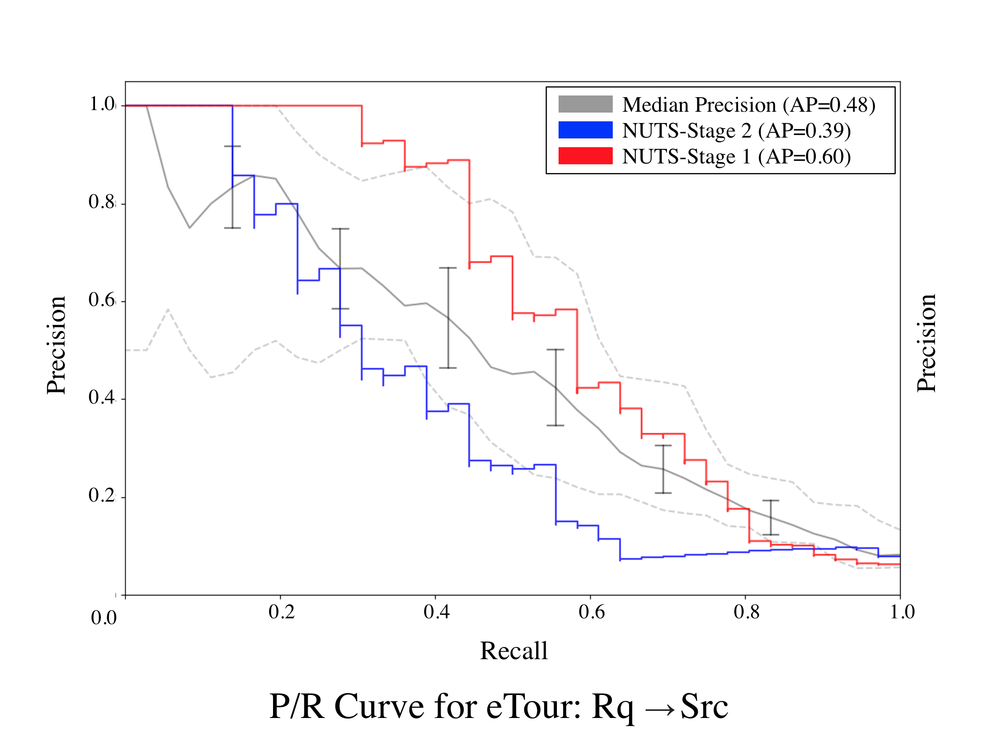
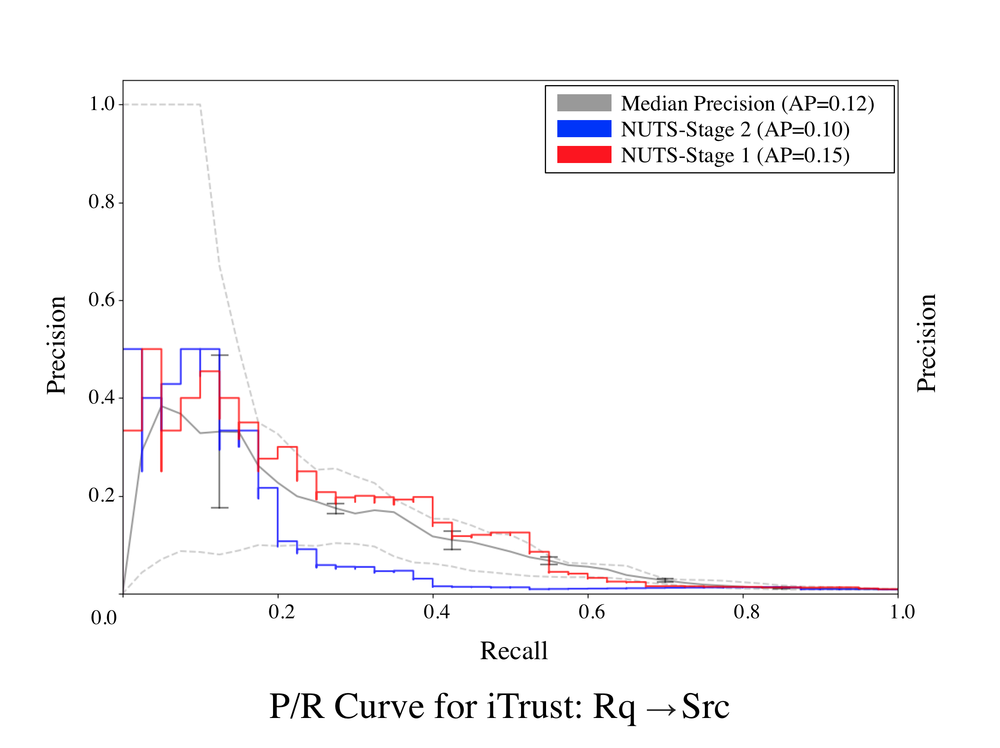

RQ3 Results
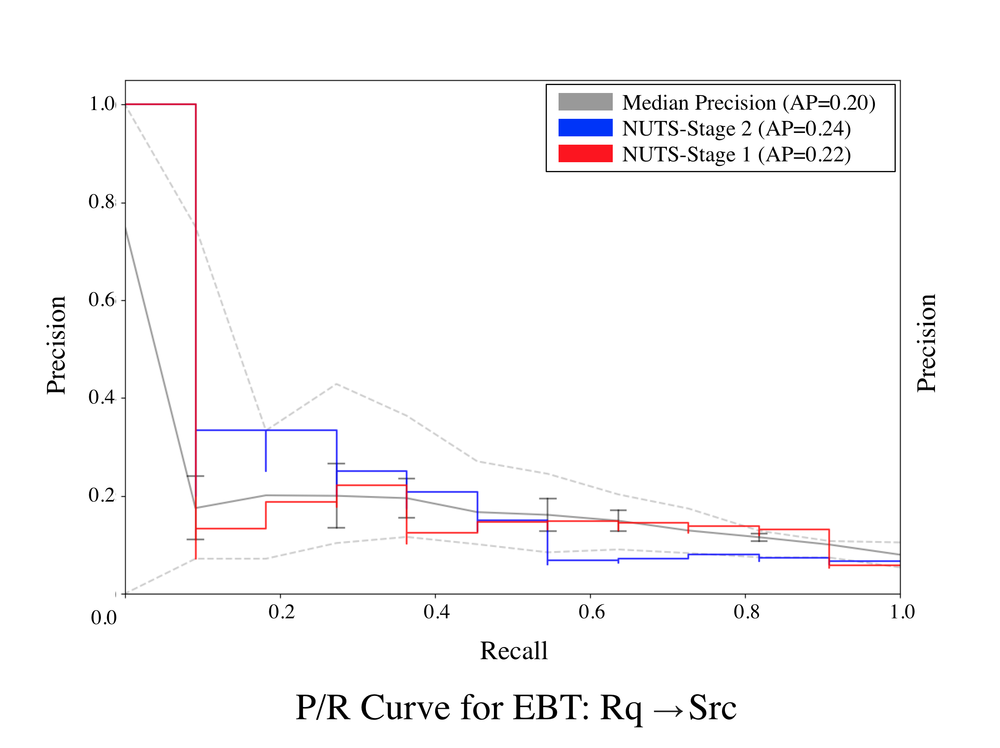
The Figures below present the P/R curve for Stage 3 of Comet’s HBN for our six subject systems’ links that were found to have transitive relationships for both τ =0.55 and τ =0.65. The results show that, in general, for τ =0.65 for Comet’s Stage 3 model, the accuracy of Comet’s predicted trace links improve, with four of the six datasets showing improvements. For τ =0.55 the results generally exhibit similar or slightly worse performance compared to Stage 1. The fact that the higher value of τ led to better performance improvements is not surprising, as this parameter essentially controls the degree of relatedness required to consider transitive relationships. Thus, a higher value of τ means that only highly similar transitive requirement relationships are considered by Comet's model. Using a lower value for this parameter might introduce noise by incorporating transitive relationships between artifacts that don't have as high a degree of similarity. The LibEST (Rq→Src) dataset exhibited decreased performance for τ =0.65, however this is likely because the requirements for this industrial dataset are based on formal format from the Internet Engineering Task Force (IETF). The somewhat repetitive nature of the language used in these requirements could lead to non-related requirements being transitively linked, leading to a decrease in performance. This suggests leveraging transitive relationships between requirements leads to larger performance gains for more unique language. Overall, our results indicate that Comet’s Stage 3 model improves the accuracy of predicted trace links for a majority of our subjects.
Precision/Recall Curves for Req-Req Transitive Links T=0.50
(Right click to download an image or open in new tab/window at full size)





Precision/Recall Curves for Req-Req Transitive Links T=0.65
(Right click to download an image or open in new tab/window at full size)





RQ4 Results
The P/R curve results for the the holistic Comet (Stage 4) model are given below. These results show that Comet’s holistic model outperforms the baseline median IR/ML techniques, and Stage 1 for all subject programs. For three subjects (LibEST Req→Src, EBT, and iTrust), Comet's holistic model matches or outperforms the best baseline IR/ML technique. The P/R curve for the LibEST (Req→Src) dataset illustrates that the performance gains in prediction precision extend for a large range of recall values. The results of these experiments demonstrate that Comet’s holistic model is able to effectively combine information from multiple sources to improve its trace link prediction accuracy.
Precision/Recall Curves
(Right click to download an image or open in new tab/window at full size)

RQ5 Results
Figure 2 provides the responses to the likert-based UX questions from the six developers who work on the LibEST project after interacting with the Comet plugin. Table 3 provides the full set of usability questions asked to developers, as well as the questions that helped to guide the semi-structured interviews with project managers. We provide selected samples of responses to these questions. Overall, the responses from these developers were quite positive. They generally agreed the Comet plugin easy to use and understand, but more importantly, generally found the accuracy of the predicted links and non-links to be accurate. Additionally, we highlight representative responses to the user experience questions. Overall the developer responses were encouraging, indicating the practical need for approaches like Comet. For instance, one developer stated their need for such a tool, “I really want a tool that could can look at test cases and requirements and tell me the coverage. That way the team can know whether we are missing functionality or not.” Another developer explained the need for a feature that incorporates developer feedback, stating the importance of the “ability to describe or explain how the code matches up with the code for future reference. Discussion/comments about such explanation as different developers might see links that others don't”, whereas another developer stated, “Being able to provide feedback is useful and seeing it update the percentage immediately was nice.” This indicates that the support for developer feedback and responsiveness of the Comet plugin inherently useful. Developers also found the traceability report to be useful, with most criticism suggesting practical UI improvements. For instance, developers appreciated “The fact that there were the three different options for viewing the traceability between different [artifacts]”, and “The ability to bring up the specific requirement quickly in the same window”. These responses point toward the need for automated approaches in practice and illustrates the utility developers saw in the Comet plugin.
We also collected feedback that validated the importance of the practical use cases that the Comet plugin enabled. In these interviews, the teams generally stated that Comet would be very useful for code auditing, as one manager stated that it would “allow compliance analysts to [inspect] links, look at the code and validate [the links]”. Furthermore, a team responsible for security audits of systems found an interesting use case for Comet that is often overlooked in traceability analysis. That is, they were interested in code and requirements that are not linked to any other artifact, as such artifacts are likely to be suspicious and should be inspected further. In this case, Comets predictions of non-links would be just as important as the predication of links. Overall, the interviewed teams saw great promise in Comet, and we are working to further integrate Comet into real workflows.
| Usability Questions for Developers | Response Type |
|---|---|
| What parts of the tool did you find most useful? | Free Response |
| What other information (if any) would you like the tool to provide? | Free Response |
| What elements did you like the most from the tool? | Free Response |
| Do you have any suggestions for how the tool may be improved? If yes, please elaborate. | Free Response |
| Interview Questions with Project Managers | Response Type |
| Can you give an overview of how your team currently practices traceability? | Semi-Structured Interview |
| Do you use any tools to help with traceability? Can you tell me what they are and how you use them? | Semi-Structured Interview |
| What are the most common formats for your requirements? | Semi-Structured Interview |
| What are the most important artifcts to link together for your team? | Semi-Structured Interview |
| What are the hardest parts of the software traceability process for your team? | Semi-Structured Interview |
| Would a tool that helps to automate this process be useful for you? What features would you like to see in such a tool? | Semi-Structured Interview |
| Does our automated tool look like something that your team would like to use? | Semi-Structured Interview |
| Does the tool look too complex? | Semi-Structured Interview |
| Do you think the features and UI are easy to understand? | Semi-Structured Interview |
| Does the tool look difficult to navigate? | Semi-Structured Interview |
| What part of the tool seemed most useful to you? | Semi-Structured Interview |
| Are there any other types of information or features that you would like to see in the tool? | Semi-Structured Interview |
| Do you have any suggestions for improving the tool? | Semi-Structured Interview |
Results for LibEST Case Study UX Questions
